
AI 时代下开发模式的转变
Table of contents
软件的开发模式正在被彻底颠覆,我想和大家分享一下这个过程和我自己的一些感受。
1️⃣ 大教堂、集市、神秘屋
1997 年 Eric Raymond 写了一本软件开发模式的书籍《大教堂与集市》,把当时的软件开发分成两种模式,从后视镜看,之后近30年的所有软件其实都遵循着这两套模式。
大教堂模式:像中世纪建大教堂一样,由少数专家精心规划,封闭开发,严格管控。需求、设计、实现、测试每一步都有评审,源代码在开发期间不对外界公开,隔很长的周期才发布一个大版本。所有的商业软件基本都是这么造出来的,代表作是:Windows 和 Oracle,它的质量来自流程管控,代价是慢。
集市模式:开放平台,所有人都可以参与,开发过程完全透明,靠大量参与者的眼睛保证质量, Raymond 把这个总结成 Linus 定律:只要眼睛足够多,所有 bug 都是浅的,Linux 是代表作。
集市模式解决了一个看起来无解的问题:几千个互不隶属、没有雇佣关系的人,怎么把一个上千万行代码的项目维护几十年不散架,因为随着时间的积累,参与的人特别多,代码量也越来越大,项目维护的难度其实是指数上升的,这个答案是辖区制治理。
大家如果做过开源的话就知道这个模式是怎么运行的,以 Kubernetes 为例子。整个社区拆成二十多个 SIG(Special Interest Group),代码树里每个目录都放着一份 OWNERS 文件,写明这个目录的 reviewer 和 approver 是谁,PR 必须拿到对应辖区 approver 的批准才能合入。
大的功能变更要先提 KEP(Kubernetes Enhancement Proposal),由相关 SIG 评审通过才能动手,贡献者从 member 到 reviewer 再到 approver,一级一级凭历史贡献爬上去。
Linux kernel 也是同样的思路,MAINTAINERS 文件划定每个子系统的维护者,patch 逐级向上合入,最后汇到 Linus 手里。
靠这套机制,一个没有统一雇主的开源项目能维持几千个活跃贡献者、十年以上的工程质量。
大教堂和集市覆盖了过去三十年几乎所有的开发方式,它们有一个共同前提:代码是人一行行写出来、一行行 review 进去的,我们现在管这个叫古法编程。
Agentic AI 把第三种模式带了出来,有人叫它称为神秘屋。
这个名字来自加州圣何塞的温彻斯特神秘屋,枪械大亨温彻斯特的遗孀 Sarah Winchester 从 1884 年起在这栋宅子上连续施工 38 年,没有总设计师,没有完整图纸,想到哪建到哪。
最后这栋房子有 160 个房间,有通向天花板的楼梯,有打开是一堵墙的门,二层还有一扇悬空的 Door to Nowhere。没有任何人知道它的全貌,但它确实一直在长大,而且能住人。

温彻斯特神秘屋,加州圣何塞(图源:Wikimedia Commons)
神秘屋模式下的软件就是这样:
- 需求是自己提的,想要什么直接让 AI 去做,没有需求评审
- 代码、测试用例、文档可能全部由 AI 生成
- 项目规模快速膨胀,架构谈不上优美,整体偏臃肿
- 最关键的是,没有任何一个人搞得懂全貌和细节,包括项目的主导者。
这听起来很糟糕,但神秘屋一定会成为主流的开发模式,它的效率和前两种模式不在一个数量级上,本质上是一种范式级别的突破。
2️⃣ 神秘屋有多快
先介绍一下Peter Steinberger。他是PSPDFKit 创始人,卖掉公司退休后又复出,2025 年底做出了开源项目 OpenClaw,2026 年 2 月加入 OpenAI,他是目前把神秘屋模式推到最极限的人之一。
第一组数字:commit 密度。 今年二三月,还在 GPT-4.6 时代,他就做到了平均每十分钟提交一次代码。一天总共 144 个十分钟,意味着他就算二十四小时不睡觉,每个十分钟都要产出一段能提交的工作,这个频率靠手写在物理上就是不可能的。
代价是几乎每个版本都出过fatal级别的 bug,但这些 bug 修起来也快,基本当天处理完,很少过夜。
下面是 OpenClaw 仓库 2 月 8 日到 3 月 8 日的 GitHub Pulse。一个月里 921 个作者往 main 推了 8494 个 commit,他一个人占 4878 个,平均一天 160 多个;同期 6365 个活跃 PR、12462 个活跃 issue,main 上改动了 6826 个文件,新增 81.9 万行、删除 23.4 万行。
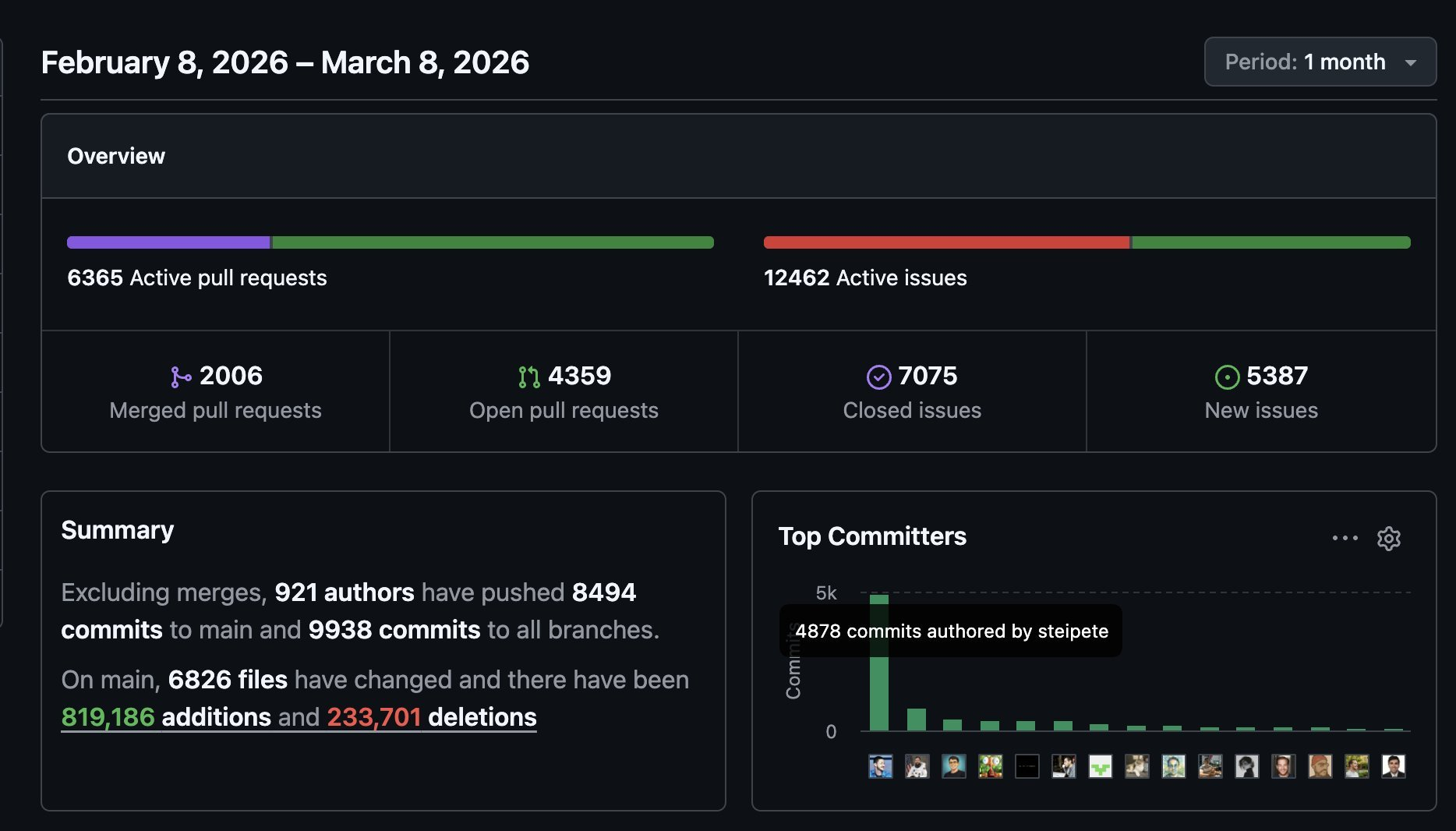
OpenClaw 仓库一个月的 Pulse:steipete 一人 4878 个 commit
第二组数字:token 账单。 今年 5 月他晒出了自己 30 天的 API 用量面板:130 万美元,6030 亿 token,760 万次请求,背后是大约 100 个并行的 Codex Agent,而操作这些 Agent 的人只有 3 个。
这些 Agent 在干的事包括:review 每一个 PR,扫描每一个 commit 的安全漏洞,给 issue 去重,写修复,盯 benchmark 回归并把异常报到 Discord,甚至旁听团队会议,把会上讨论到的功能直接开成 PR。
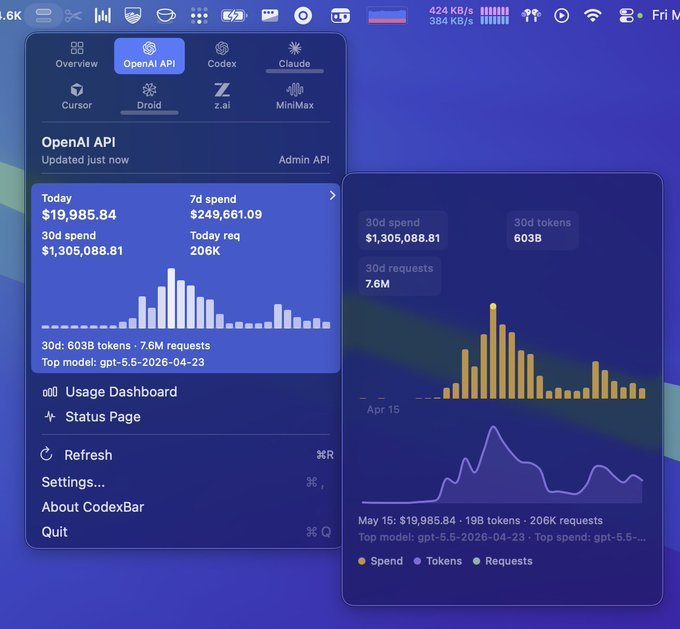
CodexBar 用量面板:30 天 $1,305,088.81,6030 亿 token,760 万次请求,top model 是 gpt-5.5
需要说明,token 消耗量不等于 AI 产出,这里面有大量探索、重试和被丢弃的分支,但两者肯定是正相关的。3 个人调度 100 个 Agent,消耗 130 万美元的算力来推进一个项目,这个组织形态在两年前根本不存在。
第三组,Anthropic 自己的发布频率。 有人把 Anthropic 从 2 月 1 号到 3 月 24 号之间的所有产品发布,一条一条扒了出来,按日期、按功能、按工程师归属做了一张完整的 shipping calendar,最后的数字是,52 天,74 个产品发布,平均不到 17 个小时出一个:Claude Code 28 次,Cowork 15 次,API 和基础设施 18 次,模型和核心平台 13 次,所有产品线并行往前推。
这个节奏到现在也没停:4 月 16 号 Opus 4.7,第二天 Claude Design,5 月 28 号 Opus 4.8 和 Claude Code 动态工作流,6 月 9 号 Fable 5。

Paweł Huryn 整理的 52 天发布日历,每条发布标注了对应的工程师(来源:productcompass.pm)
3️⃣ 为什么神秘屋模式一定会赢:从人月神话说起
《人月神话》里 Brooks 有个统治了软件工程五十年的论断:给延期的项目加人,只会让它更延期,因为 n 个人的沟通路径是 n(n-1)/2 条,人越多,花在对齐上的时间越多。
他还区分了偶然复杂度和本质复杂度,偶然复杂度来自具体实现,比如语言、工具、框架的限制;本质复杂度来自问题本身。过去几十年,高级语言、框架、自动化测试不断降低偶然复杂度,但本质复杂度没有上限,随着系统增长,组件之间的交互面会以组合方式扩张。
结论就是,对一个项目来说,传统开发模式的人力投入存在临界点,越过临界点之后,新增的人力不仅帮不上忙,反而是负贡献。
这也是为什么很多组织会把一个小组的规模控制在 10 人上下,亚马逊的 two-pizza team 是 6 到 10 人,Scrum 官方指南建议整个团队不超过 10 人,背后是同一笔账:10 个人是 45 条沟通路径,15 个人就是 105 条,人数加一半,对齐成本翻了一倍还多,新加入的人很快就发挥不出作用了。
这个结论可以形式化地推出来,论证分三步:先给传统软件系统和 AI Agent 系统两个精确定义,再证明传统范式的复杂度增长和人类认知容量之间存在结构性错配,最后比较两种范式的扩展性。
定义 1:传统软件系统。 一个传统软件系统 S 是三元组:
S = (C, D, E)其中:
C是一组计算资源,包括 CPU、内存、I/O;D是编码在源代码中的一组确定性决策规则;E是执行环境,它根据输入对D求值并产生输出。
关键属性是:D 相对于执行过程是静态的。也就是说,所有决策逻辑都必须在人类工程师遇到任何输入之前被显式写出来。
在这个定义下,每一次功能增加、每一次 bug 修复、每一次对环境变化的适配,都要求人类完成四件事:理解需要改变什么,定位 D 中正确的位置,在不引入回归的前提下修改逻辑,并验证正确性。每次变更的成本,是 D 的规模和其内部依赖密度的函数。
命题 1:复杂度扩展。 对一个包含 n 个组件的系统,如果每个组件都可能和其他组件交互,那么可能的交互路径数量 P(n) 会呈指数级增长:
P(n) ∈ Θ(2^n)P(n) 的量级是 2 的 n 次方。当 n 足够大时,P(n) 的增长速度和 2^n 同一量级,既不会更快也不会更慢。直观理解就是,每往系统里多加一个组件,可能的交互组合大致翻一倍,加 10 个组件,复杂度上界就翻了 1024 倍。原因是,在 n 个组件之间,每一对组件都可能存在或不存在有意义的交互,从而形成大量可能的依赖图。现实系统不会实现所有配置,但复杂度上界呈指数增长;与此同时,人类用于推理这些交互关系的认知能力基本是常数。
这种错配,是软件项目在规模变大后边际生产率下降的深层结构原因。传统应对方式是层级分解、模块化接口和封装、引入设计模式、分布式微服务等等。这些方法可以降低常数因子,却不会改变渐近行为。
定义 2:AI Agent 系统。 一个 AI Agent 系统 A 是四元组:
A = (M, T, Mem, Π)其中:
M是作为推理引擎的大语言模型;T是一组可执行工具,包括代码解释器、API、数据库、文件系统;Mem是记忆子系统,包括短期上下文和长期向量存储;Π是规划机制,它把用户意图分解为行动序列。
系统以迭代方式运行:模型根据当前状态和记忆选择行动,执行行动后进入下一状态。关键差异在于,在 Agent 系统中,决策逻辑是在运行时生成的。LLM 可以动态生成代码、调用工具,并根据中间结果调整行为,这些都不需要提前逐项编程。它生成的代码不是系统本身,而是临时产物:需要时生成,不需要时丢弃。
扩展性比较。 设想一个任务 T,其解决方案需要在规模为 N 的空间中推理。
在传统范式下:
- 人类工程师必须在心智上遍历这个空间,识别解决路径;
- 该路径必须被编码成静态程序;
- 人类认知容量
C_H基本固定; - 当
N > C_H时,这个任务在现实成本下不可行。
在 Agent 范式下:
- LLM
M负责遍历空间,其有效容量C_M会随模型规模和训练算力扩展; - 规划机制
Π把任务T分解成子问题,每个子问题可独立处理; - 代码只针对具体解决路径生成,而不是为所有可能情况提前编写;
- 随着 LLM 能力提升,
C_M也随之增长。
这套推导落到结论上就是两点。
一,Agentic AI 没有沟通成本。 Brooks 的 n(n-1)/2 是对人成立的,Agent 之间传递信息是上下文秒级同步,而所谓的对齐,大部分时间其实就是在读文档:需求文档、设计方案、代码、commit 历史,人要开半天会才能同步完的信息,它几秒钟就读完了。不需要开会对齐,加十个 Agent 不会让项目更慢。
二,Agentic AI 更能扩展。 人类认知容量 C_H 是常数,模型的有效容量 C_M 随规模和算力增长,Agent 范式把解决问题的能力从人类的认知限制中解放出来,规模上可处理的问题类型发生了质变。
4️⃣ AI 时代开发的新特性具体有哪些?
代码成了黑盒:委派,而非指示
你要做的是理解需求,把验收标准描述清楚,代码本身,从需要逐行理解的对象,变成了只要结果正确就可以接受的黑盒。
这和 Claude Code 官方最佳实践文档里的理念是一致的,文档开篇的原话是:you describe what you want and Claude figures out how to build it,你描述你要什么,让它自己想怎么实现,也就是委派,而非指示(delegation, not instruction)。给 Agent 的应该是目标和验收标准,让它自己找实现路径,完成后要求它交出证据,测试输出、跑过的命令和返回结果,而不是人替它规划每一步、再逐行检查它的产出。文档里甚至建议用另一个独立的 Agent 来复核结果,干活的不给自己打分。
测试用例是新的护城河
今年三月有个标志性事件。一个 Cloudflare 工程师宣布,他用一周时间用 AI 重新实现了 Next.js,取名 vinext。实际上第一天晚上基本功能就出来了,后面几天在修边界、补测试,最后 API 覆盖率 94%,构建速度比原版快 4 倍,客户端包体积小 57%,现有应用不改一行代码就能直接跑,token 总花费 1100 美元。
Next.js 背后是 Vercel,一个大型团队做了整整十年,去年收入两亿美元。
代码不是护城河了,测试用例才是。
vinext 能复刻成功,靠的是 Next.js 有完备的文档和完整公开的测试用例,AI 实现的每个 API 只要能通过原有的接口测试,就能确认百分百兼容。反过来,拿不到测试用例,谁敢说行为一致,谁敢放到生产环境跑。
SQLite 是最好的例子。它本身 15.6 万行代码,测试用例 9205 万行,是代码的 590 倍,其中最核心的 TH3 测试套件闭源,专门覆盖航空、医疗这些行业的极端 corner case。正是这些不公开的用例,让 SQLite 至今复刻不了,前阵子 tldraw 也宣布准备把测试用例闭源。
那些用例里藏的是十几年踩过的坑和对业务边界的全部理解,代码可以一周生成,测试用例生成不出来。
AI 的上限取决于你给它的视野和权限
大家对 Agentic AI 强大程度的感知差异巨大,有人觉得它能独立交付需求,有人觉得它写的代码是不可用的。
我的看法是,差异最大的来源,是你赋予了它多少能力,它能看到什么、操作什么。
先说视野,最近很多人提倡回归 monorepo,放弃微服务那种多仓拆分,本质就是为了让 AI 一眼看到所有东西。它只能看到单个仓库时,不知道下游怎么用、上游给什么,准确率会大幅下降,AI 能看到的世界就是你给它的那个目录。就算上下游有详细的文档,可能也不如直接让 AI 看到整个仓库来得更真实、更详细。
视野不只是代码,还有你的私有数据,知识库是最典型的一块。
就比如知识库和笔记这类产品,现在已经有足够 AI Native 的替代方案了,就是数据放本地;如果追求视觉体验和管理方便,可以套一个 Obsidian 这类软件,让 Markdown 读起来舒服一些;三,只有数据放在本地,AI 才能最有效地获取你的所有信息,你不给它私有数据,它就只能基于通用的公开语料推理,最后生成一堆正确的废话,喂给模型的东西才是你自己的。
我之前用了三四年语雀,存了大约两三千篇文档,加起来数千万字。导出的时候非常痛苦,平台想把资产绑在云端,设了很多限制:必须分批导出,单次上限还很低,导出来的还是语雀内部格式的 Markdown,要再过一遍转换工具才能变成标准格式,我花了好几个小时才全部挪出来。
再说回权限,同一个 Agent,只给读代码的权限,它只能输出建议;给它跑测试和 CI 的权限,它就能自己验证自己改的东西;再给它发布的权限,它能把一个功能从开分支一路送到上线,每放一级权限,它能闭环的范围就大一圈。当然权限要配着约束给,分支保护、PR 必须过 check、生产操作可回滚,这些硬约束的能力远大于记忆的软约束。
5️⃣ 人成了新的瓶颈,也有了新的位置
从程序员的角度看,传统写代码的过程更像是解题。拆解需求、思考状态流转、设计模块之间的关系、应用各种设计模式,debug 的时候更是要在复杂系统里精准定位问题的根源。无论开发还是调试,这套流程带给人的不只是技术上的成长,更多的是一种精神上的满足感:通过思考,把一个抽象、复杂的问题变得清晰、可控,甚至优雅。
AI 生成模式下,这个逻辑变了。前面说过,我们现在对结果负责,你只需要想清楚最终要的东西是什么,中间过程可以不再过问,或者说即便去管,意义也不大了。
这背后是代码本质的转变:传统开发模式中,代码是我们意图的表达方式;AI 生成模式中,代码不再是意图本身,只是最终交付的结果。我们用自然语言、结构化的需求描述和清晰的约束条件,把意图标准地传达给 AI,再由 AI 把它转化为代码。代码变成一个只需要理解、不需要亲手书写的产物,只要黑盒的输出正确,就可以接受。
解题的活被 AI 接走之后,把开发流程画出来你会发现,现在最慢的环节是人。人在流程里的占比越小,整体速度就越快。
Caltech 的 Markus Meister 实验室 2024 年在 Neuron 上发过一篇论文,标题就叫 The unbearable slowness of being,他们量化了一笔账:人的感官系统每秒接收大约 10 亿 bit 的信息,但思维真正处理信息的速度只有每秒 10 bit 左右,中间差了 8 个数量级。这也从机制上解释了为什么人在同一时刻只能处理一件事,那些看起来能一心多用的人,只是任务切换比较快,制造了并发的错觉,和 CPU、GPU 的真并发完全是两回事。
为了保持每个对话上下文的整洁,大家现在普遍同时开多个 session,同时指挥多个 Agent 并发干活,真正的瓶颈变成了并发处理,而这恰好是人脑天生不擅长的。
另一个瓶颈是信息输入的速度,任务结束时 AI 会丢给你一份 markdown 或者一屏终端输出,你要确认它到底干了什么。
AI 时代的开发速度,瓶颈早就从生成那一侧挪到了人消化结果的这一侧。
不过说人是瓶颈只讲了一半,瓶颈的另一面是位置:AI 做不到的事,就是人该站的地方。
今年有个叫 EvoClaw 的基准测试,不考孤立的 issue 修复,考连续演化,让 Agent 沿着 commit 历史持续开发,错误会累积。结果是 12 个前沿模型、4 个 Agent 框架,在孤立任务上成功率超过 80%,一进连续场景,最高只剩 38%。
代码库超过上下文窗口后,它会忘掉系统级的不变量;早期一个小错误会在后续工作里滚成复合失败;它没有技术债的概念,只优化眼前这个任务的完成;测试全绿,语义可能还是错的。这些问题目前都没有现成解法,长上下文的状态管理(怎么大规模压缩、索引和检索相关上下文)、开放场景的验证(当前基准测的是孤立正确性,真实系统要求安全性、可靠性、可维护性在时间维度上都有保证)、多 Agent 协作时的集体行为对齐,都还是开放问题。
这些距,就是现阶段人的位置。
- 定义什么要做
- 定义什么叫好
- 把验收标准变成 Agent 能自我校验的测试
- 守住架构和长期不变量
- 以及在 AI 反复尝试都搞不定的线上故障面前,拿出人类工程师攒了多年的经验
6️⃣ 从个人到团队,整条研发流水线要一起快
前面说的都是个人怎么用 Agent,但团队协作才是真正的深水区和困难点。
大部分公司现在做的是 AI-assisted:工程师开个 Claude\Codex辅助编程,PM 拿 ChatGPT 写 PRD,QA 让 AI 生成用例,效率提升 10% 到 20%,但流程本身纹丝没动。
真正的AI-First 要求自上而下把流程、架构、组织围绕 AI 重新搭一遍,让 AI 当主力施工方,人负责拍板和兜底,两者的提效差距是数量级的。
为什么一定要动流程?因为产研测本质上是一体的,需求从提出到上线是一条完整且环环相扣的链路。
当 build 的时间从月级坍缩到小时级之后,链路上任何一个还停留在人肉速度的环节都会把整体卡死:
- 如果 Agent 两小时交付,但 PM 还要花几天调研写 PRD,那么产品就是瓶颈
- 如果 QA 还要三天测边界,测试就是瓶颈
- 工程两小时能上线,市场一周才发得出公告,市场就是瓶颈
如果不重构研发流程,就只是把瓶颈从上游挪到了下游十米的地方,整条链路里哪个环节卡住了,谁就是瓶颈。
落到执行层面,组织现在就可以开始做三件事:
- 识别适合 Agent 的工作流: 不是所有软件工作都同样适合 Agent 自动化,成功标准清晰、范围定义明确、已有测试基础设施的任务,是理想的、最适合Agent的工作。
- 设计评估框架: Agent 输出质量高度依赖评估信号质量、可验证的测试用例,测试框架不能只衡量正确性,还要衡量鲁棒性、可维护性和业务意图的对齐。
- 重新设计团队结构: 当个人生产力通过 Agent 杠杆倍增,团队拓扑也必须演化,更小的 Agent 编排者团队会替代更大的开发团队,也确实已经有很多组织在尝试这么做。
木桶定律在 AI 时代变得更明显了,AI 化程度最轻的那个环节,就是整个团队的天花板。
写在最后
加入光荣的进化吧。
Reference
- Eric S. Raymond,《大教堂与集市》(The Cathedral and the Bazaar),1997
- Frederick P. Brooks,《人月神话》(The Mythical Man-Month),1975
- Kubernetes 社区治理(SIG 列表与 OWNERS 机制):https://github.com/kubernetes/community
- Winchester Mystery House:https://en.wikipedia.org/wiki/Winchester_Mystery_House
- Zhenfeng Cao,The End of Software Engineering: How AI Agents Are Fundamentally Restructuring the Software Paradigm,arXiv:2606.05608:https://arxiv.org/abs/2606.05608
- Tom’s Hardware,OpenClaw creator burned through $1.3 million in OpenAI API tokens in a single month:https://www.tomshardware.com/tech-industry/artificial-intelligence/openclaw-creator-burns-through-1-3-million-in-openai-api-tokens-in-a-single-month
- Paweł Huryn,Claude Team is Shipping Like Crazy: 74 Releases in 52 Days:https://www.productcompass.pm/p/claude-shipping-calendar
- windliang,《杀死那个写代码的人》:https://windliang.wang/2026/03/31/%E6%9D%80%E6%AD%BB%E9%82%A3%E4%B8%AA%E5%86%99%E4%BB%A3%E7%A0%81%E7%9A%84%E4%BA%BA/
- 阮一峰,科技爱好者周刊第 388 期《测试是新的护城河》:https://www.ruanyifeng.com/blog/2026/03/weekly-issue-388.html
- Anthropic,Best practices for Claude Code:https://code.claude.com/docs/en/best-practices
- Jieyu Zheng & Markus Meister,The unbearable slowness of being: Why do we live at 10 bits/s?,Neuron,2024:https://doi.org/10.1016/j.neuron.2024.11.008
- G. Deng et al., EvoClaw: Evaluating AI Agents on Continuous Software Evolution,arXiv:2603.13428:https://arxiv.org/abs/2603.13428